

WebスクレイピングというとPythonのBeautifulsoupやSeleniumといったライブライを使うイメージがあったのですが、この方法だとある程度プログラミングに対する耐性と知識が必要であり、初心者には取っ付きにくいというものでした。
そこで、ここ数年の間で出てきたのが「ノンプログラミングツール」と呼ばれるもので、プログラミング知識が無い人でも直感的な作業でカンタンにプログラムを作ることが可能となってきました。
こうした動きに伴い、Webスクレイピング技術もより身近な手法となりつつあり、またWebスクレイピング技術を実装したツールも沢山出てきました。
これまでもOctoparseやGoogle Web Scraperといったソフトを使ってスクレイピングを試したことはあったのですが、今回は世界№1とされるRPAツール「UiPath」を使ってみました。
なお今回はUdemyの「UipathによるノンプログラミングWebスクレイピング ![]() 」の学習動画を参考とさせて頂きました。
」の学習動画を参考とさせて頂きました。
ターゲットサイト
今回は下図の通り楽天のデイリーランキングサイトより本カテゴリーの商品情報を抽出するプログラムを作りたいと思います。
ランキング情報をスクレイピングするプログラムを作り運用することで、日々の順位の変動なんかを追ったりできそうですね。
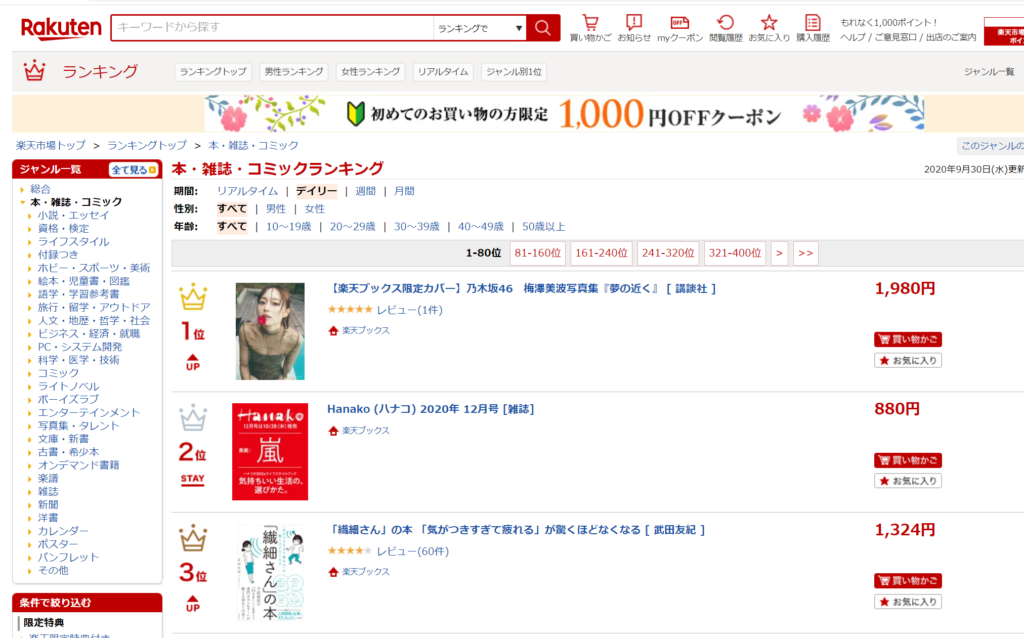
スクレイピング方法
では、早速UiPathを起動したところから進めていきたいと思います。
1.ターゲットサイトに遷移する
まずは今回スクレイピングしたいサイト、つまり楽天の本のデイリーランキングページに遷移するプログラムから作っていきます。
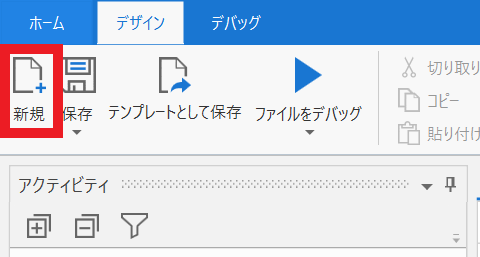
①UiPathの「新規」をクリックし、「フローチャート」を選択します
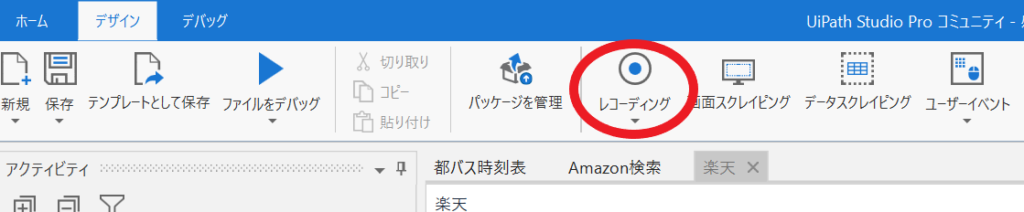
②「レコーディング」をクリックし、タブの一覧から「Web」を選択します
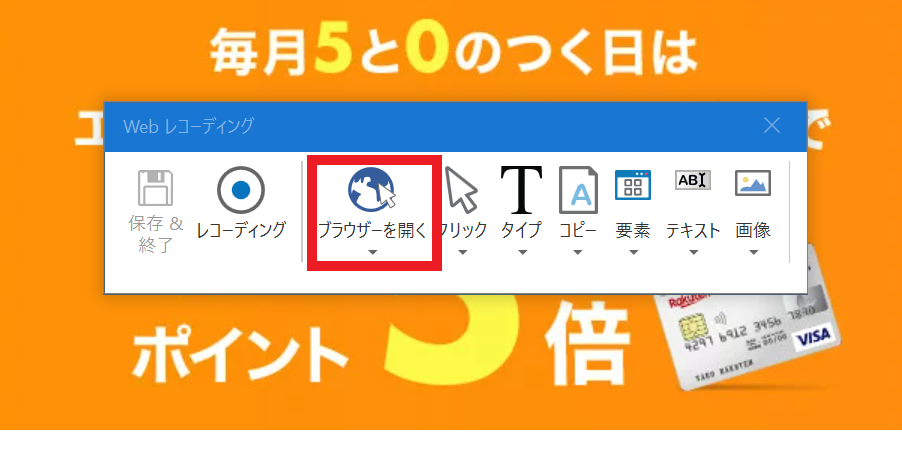
③楽天のページを開き、「ブラウザーを開く」をクリックし、タブの一覧の中から「ブラウザーを開く」を選択します
④楽天のサイト上をクリックします
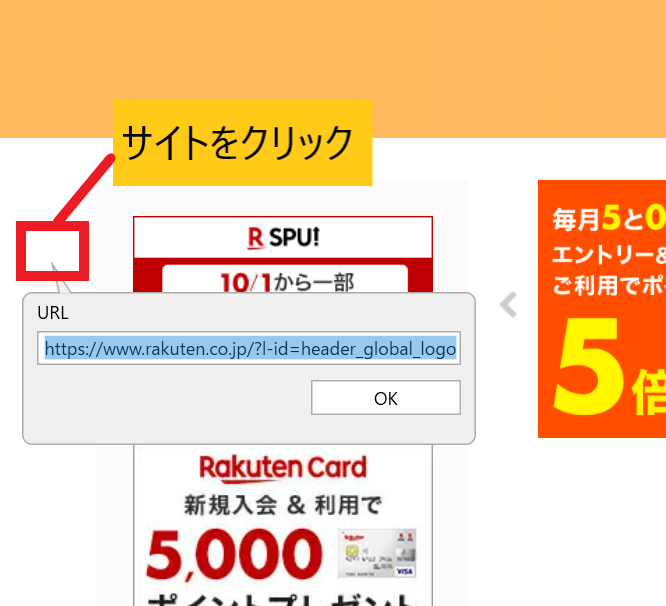
そうすると、上図のように「URL」というタブが表示されるので、OKを選択します。
⑤次に「レコーディング」をクリックし、画面の録画が始まったら、Topページの「ランキング」をクリックします

そうすると、楽天のデイリーランキングページに移るので、ここで一度Escapeボタンをクリックします。
⑥ページを下にスクロールし、「本・雑誌・コミック」が見えてきたら再度「レコーディング」をクリックし、「本・雑誌・コミック」を選択します。
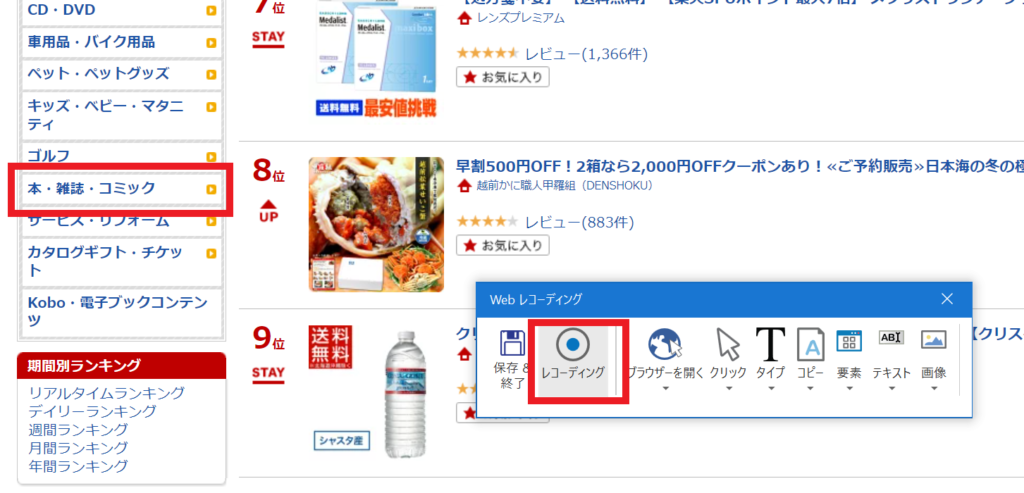
すると、「本・雑誌・コミック」のランキングページに遷移します。
これでターゲットサイトへの遷移は完了です。最後に「保存&終了」ボタンをクリックしUiPathの画面に戻ります。
2.スクレイピングする
ターゲットサイトに遷移できたら、実際にスクレイピングを進めていきます。今回は商品の「商品名」、「URL」、「価格」の情報を抽出したいと思います。
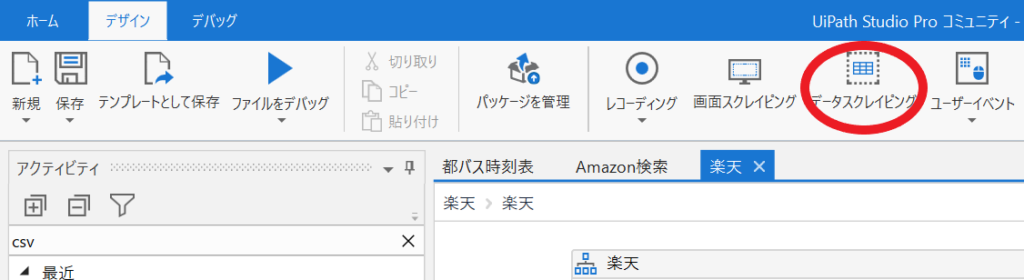
①UiPathのメニューから「データスクレイピング」を選択します
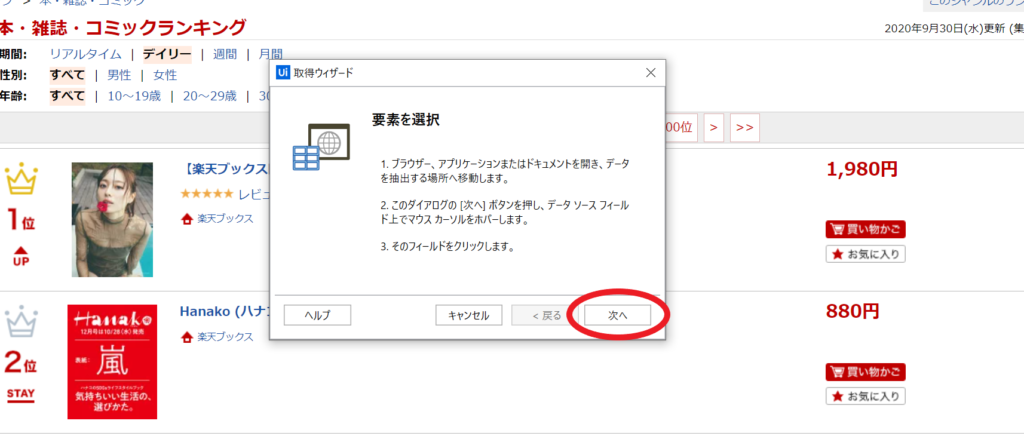
②下図のように「要素を選択」という画面が出てきたら、「次へ」をクリックします
③スクレイピングしたい情報(商品名)の先頭を選択します
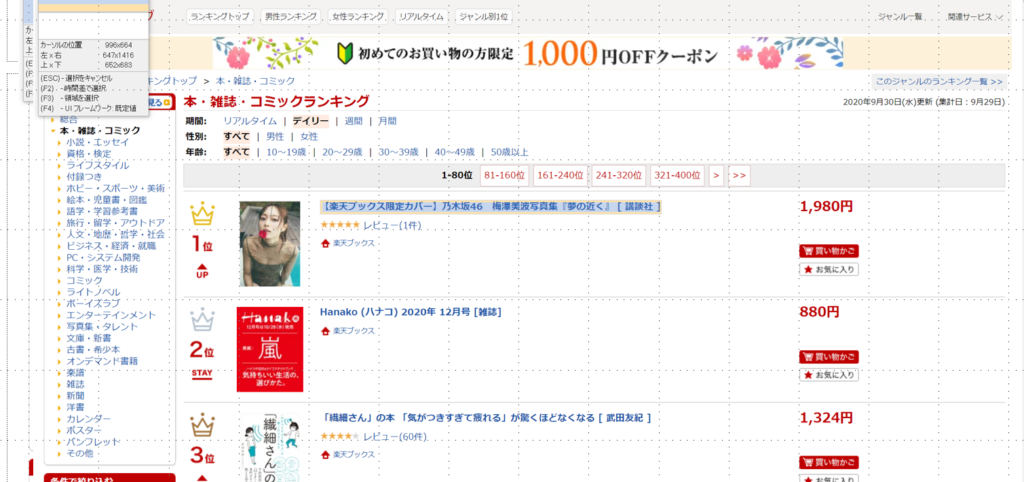
④2番目の要素を選択で「次へ」を選択します
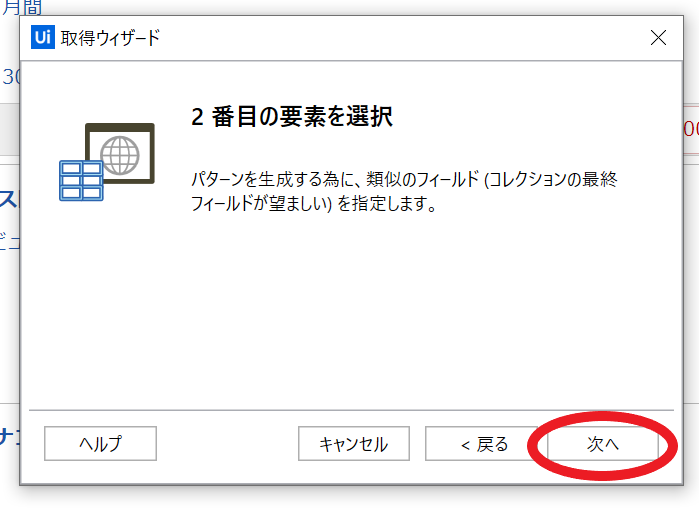
⑤スクレイピングしたい情報(商品名)の先頭の次の要素を選択します
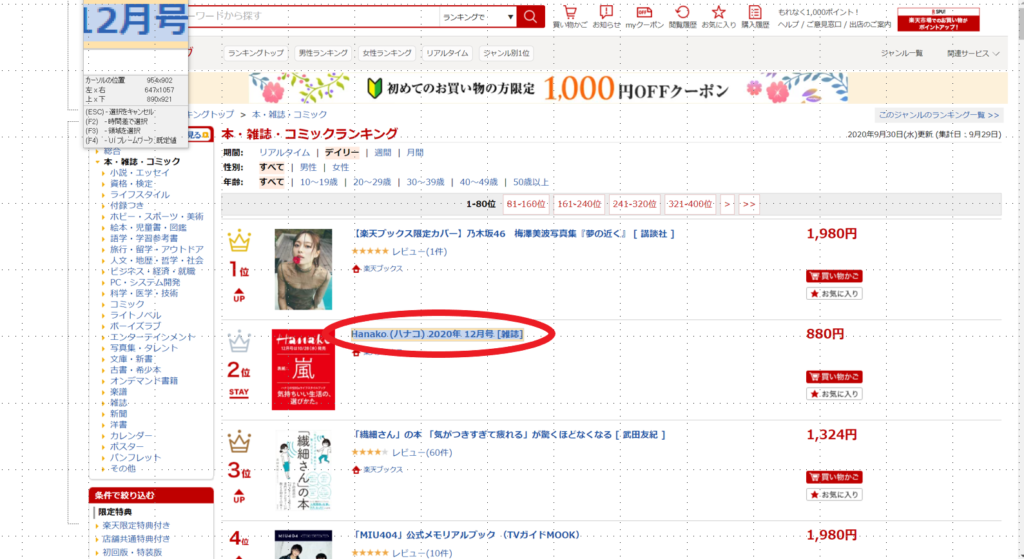
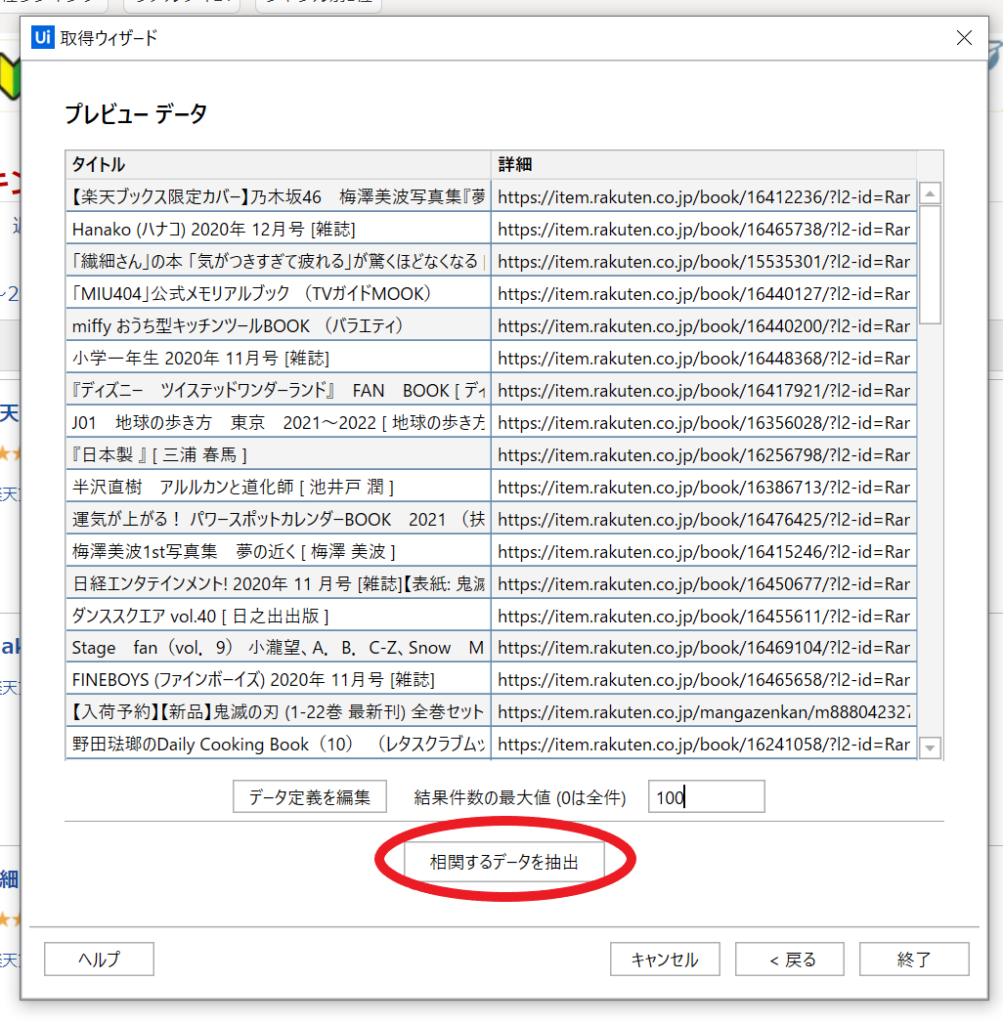
⑥取得ウィザードが開くので、下図赤枠のように情報を入力します
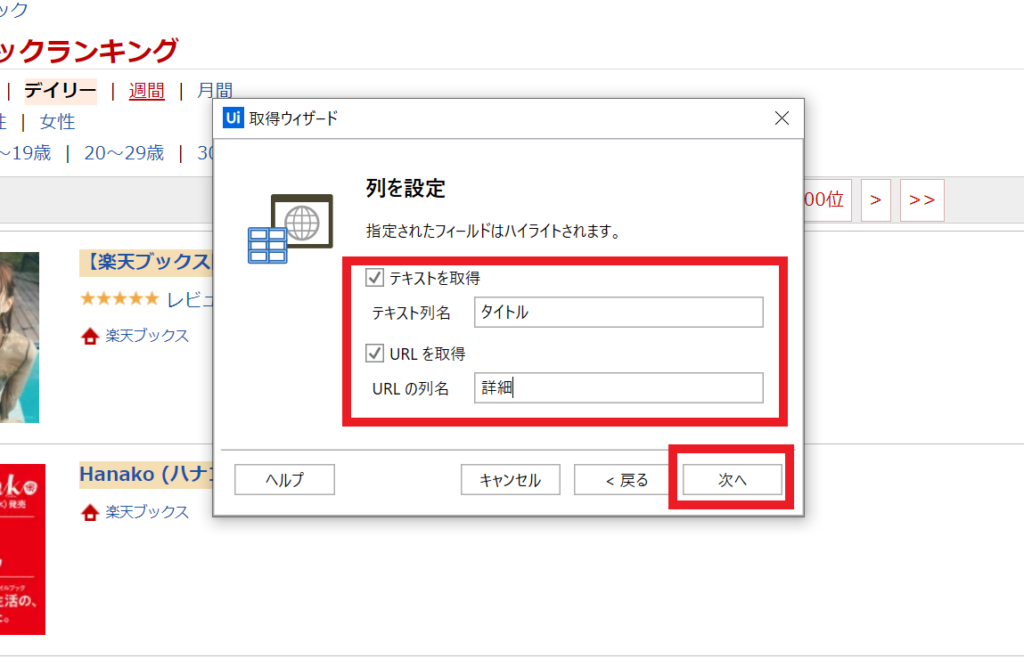
⑦下図のようにプレビューが表示されます。今のところ「商品名」の情報は取得できているようです。
次に価格情報を取得していきますが、基本的には商品名で実行したことと同じ方法です。
まずは「相関するデータを抽出」を選択します。
⑧要素を選択する
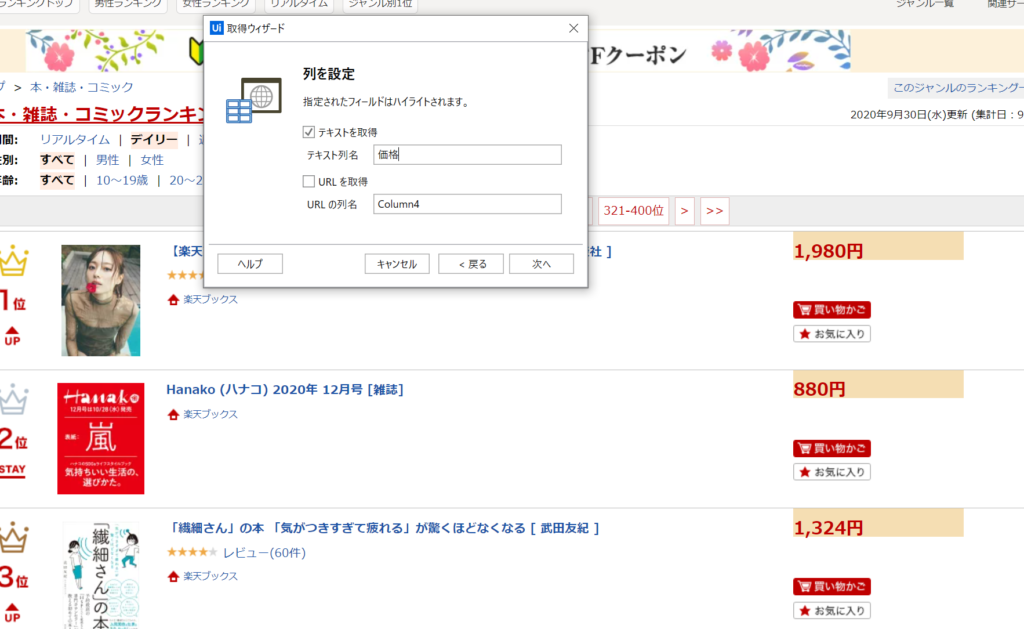
抽出したい情報(価格)の先頭部分を選択し、その次の2番目の要素を選択します。
要素が選択できたら、下図のように列名を「価格」と定義して完了です。
※UiPath画面に戻ろうとすると、複数ページの情報を抽出しますか?という注意が出てきますが、今回はいいえを選択して進みます。
3.CSVに書き込む
最後にスクレイピングした情報をCSVに書き込むフローを作っていきます。
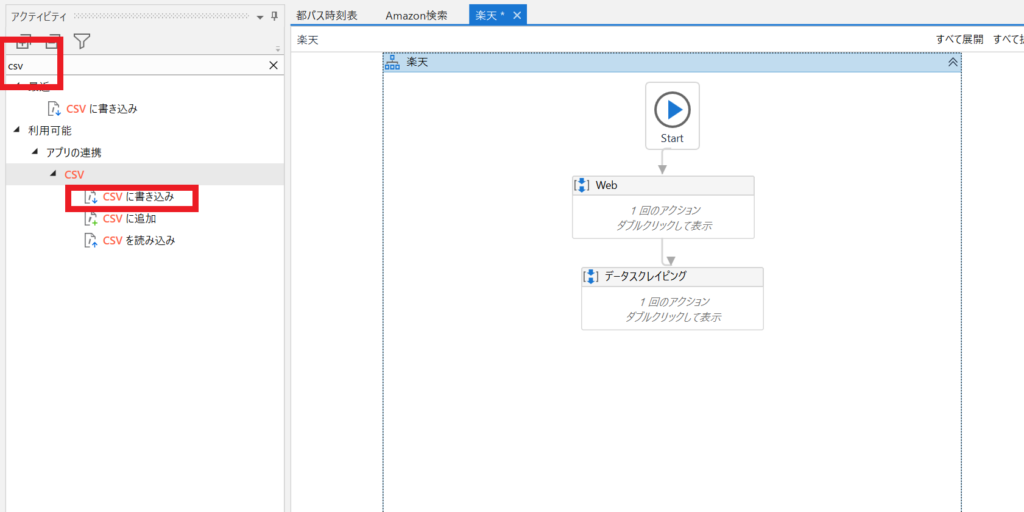
①アクティビティの検索窓に「csv」と打ち込み、「csvに書き込み」を左側のフロー図にドラッグ&ドロップします
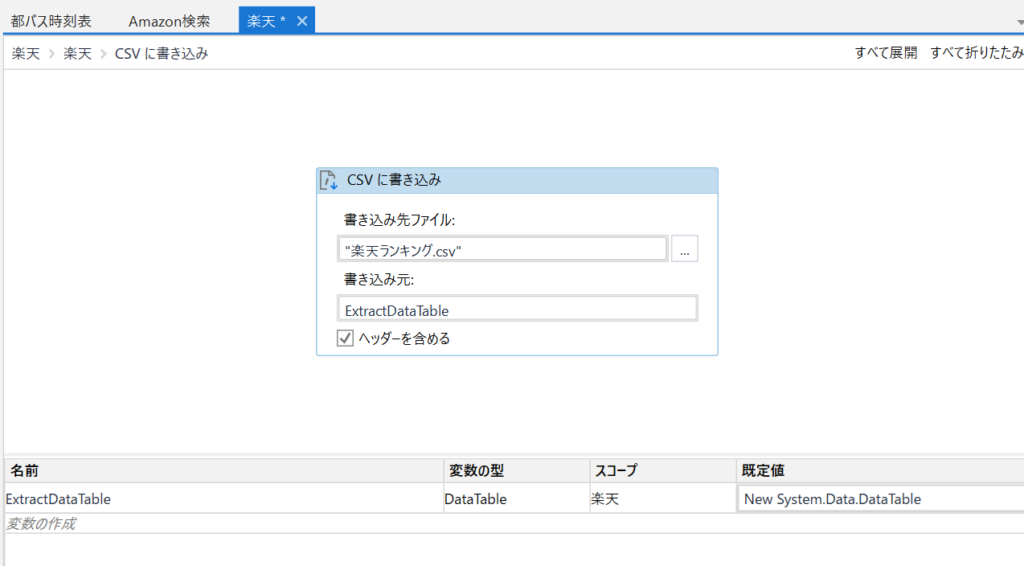
②CSVに書き込みのフローをダブりクリックし、下図のように「ファイル先」と「書き込み元(データ)」を定義します
③実行ボタンをクリック
④ファイルを確認する
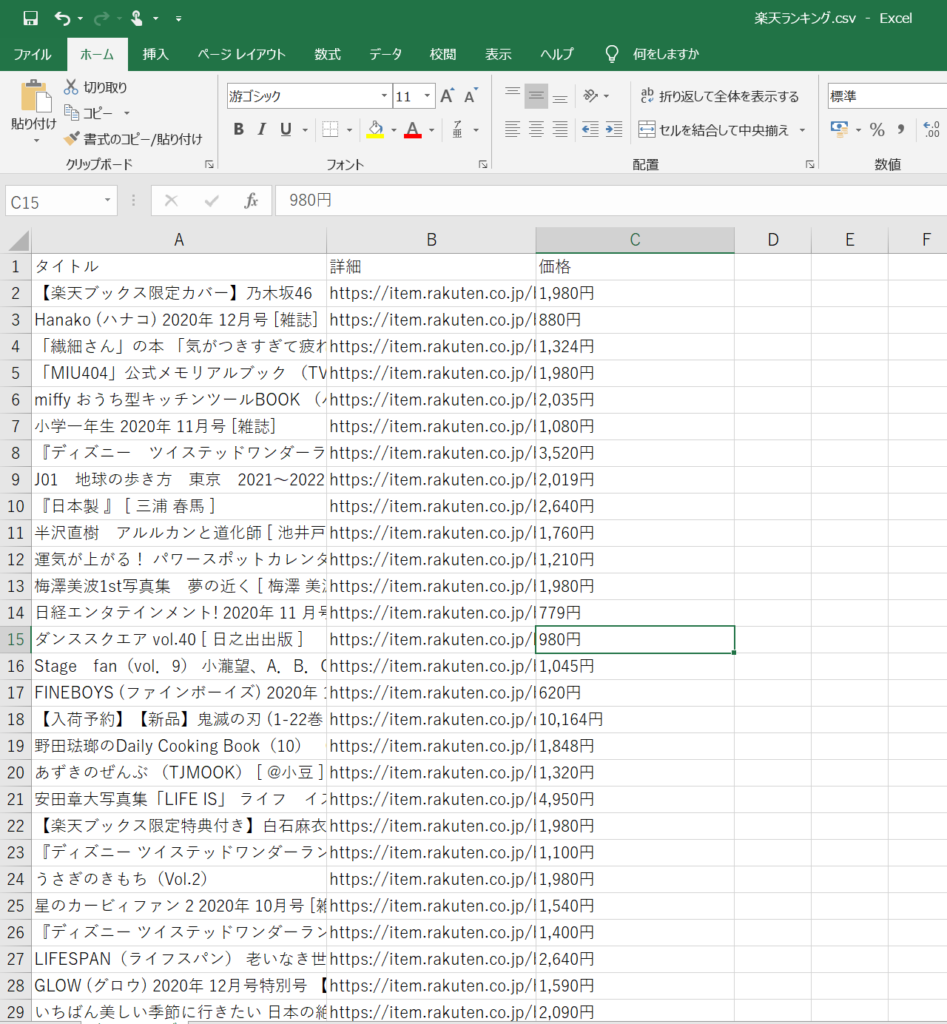
商品名の情報、商品のURL、価格情報が抽出できていることを確認出来ました。
いかがでしたでしょうか。
途中の細かい箇所ははしょってしまいましたが、こんな感じで初心者でも簡単にスクレイピングができることが伝わればと思います。
◆関連記事